Offline on Linux
Dictate into any app. Keep the audio home.
System-wide voice typing with local models. X11 and Wayland. One install command.
- Offline
- Local engines
- Display
- X11 + Wayland
- Default
- whisper.cpp
- License
- GPL-3.0
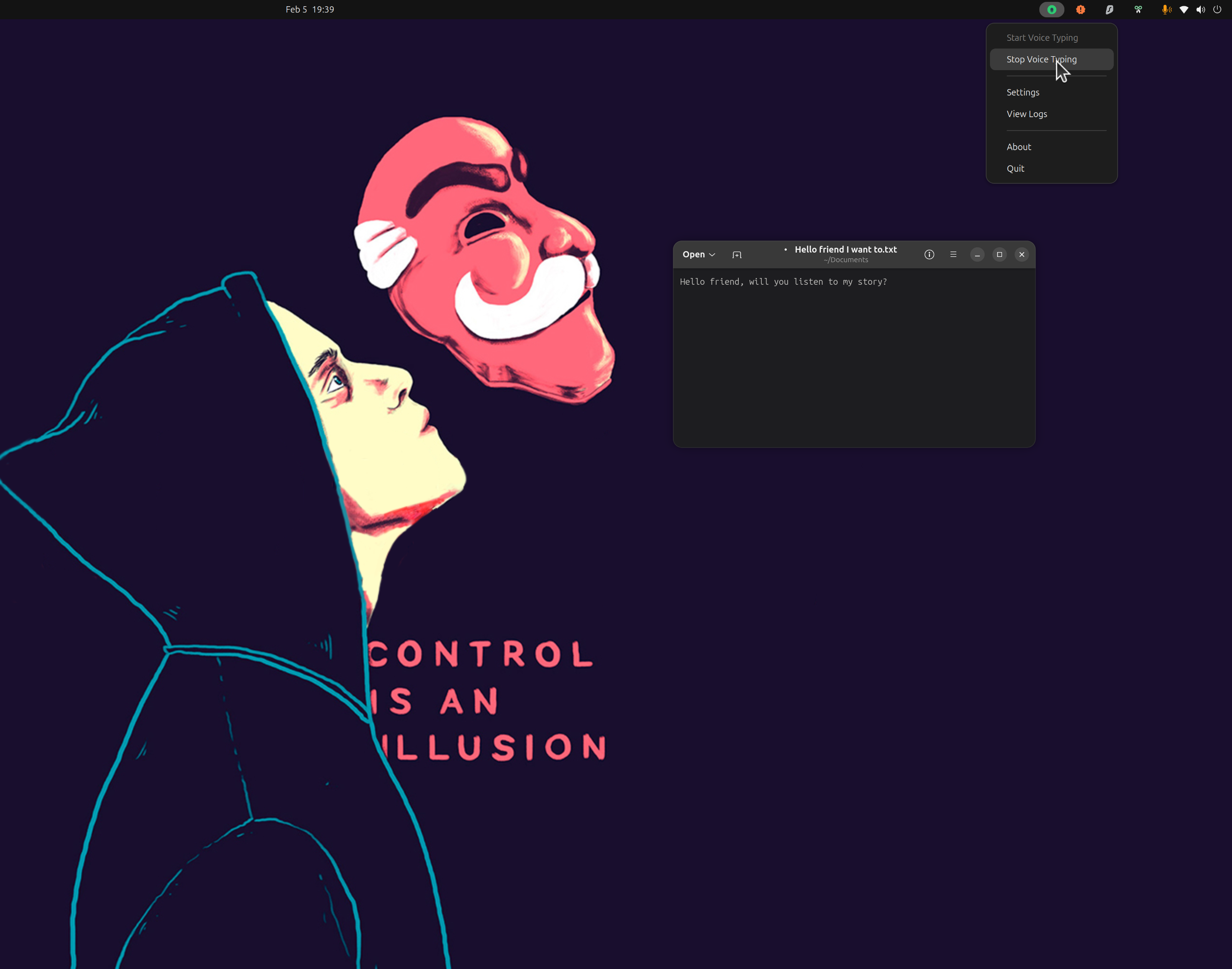
Install in one command
Interactive installer detects hardware, lets you pick an engine, and wires the desktop app.
Ubuntu · Fedora · Debian · Arch · openSUSE
$ curl -fsSL \
https://raw.githubusercontent.com/jatinkrmalik/vocalinux/main/install.sh \
-o /tmp/vl.sh && \
bash /tmp/vl.sh --interactiveBuilt for real Linux desktops
Privacy, injection reliability, and engines that match your hardware, not a cloud dashboard with a mic icon.
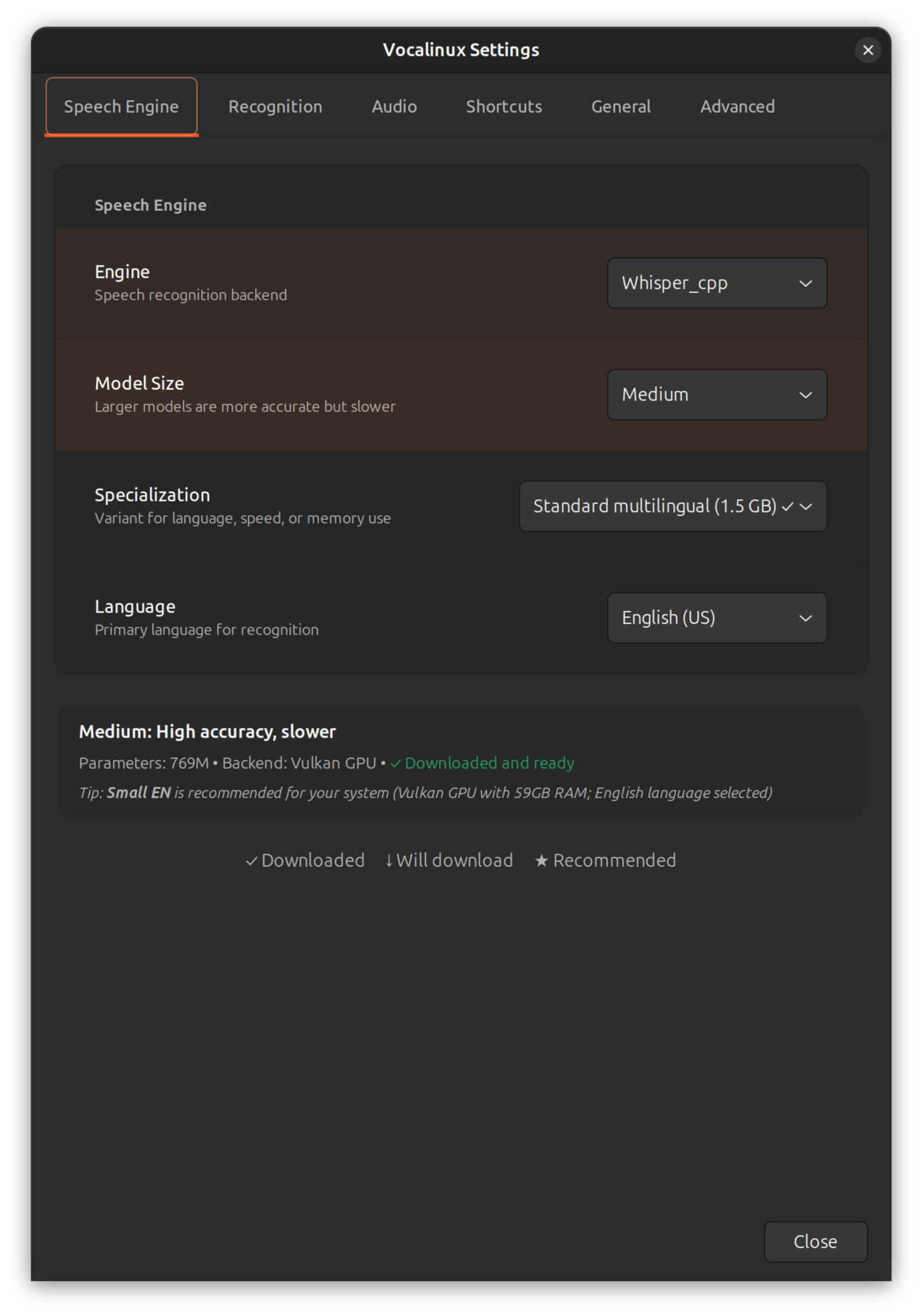
Stays on your machine
Local engines process audio on-device. No cloud upload, no telemetry, no account.
Offline privacyWorks where you type
Terminals, browsers, IDEs, office apps, and any focused text field on X11 or Wayland.
Use casesFast by default
whisper.cpp with Vulkan on AMD, Intel, and NVIDIA. Tiny model is about 74MB.
GPU accelerationYour shortcuts
Toggle or push-to-talk. Bind modifiers the way your hands already work.
ShortcutsDesktop reliability
Suspend recovery, IBus hardening, layout preservation, non-ASCII injection fallbacks.
Reliability notesNeural silence filter
Silero VAD drops empty buffers before recognition, with amplitude fallback if needed.
Voice activity detection
The Linux voice gap, closed
macOS and Windows shipped system dictation years ago. Linux users got fragments. Vocalinux is the full desktop path: tray, hotkeys, injection, and local models.
- No cloud dependency for local engines
- Works across apps, not one editor
- Guided install, not a research project
- Open source you can audit
From install to first sentence
- 1
Run the installer
One curl. It pulls dependencies, models, and desktop integration.
- 2
Pick an engine
Default whisper.cpp, or Whisper, VOSK, or a remote server you control.
- 3
Hold or toggle
Activate the shortcut, speak, and text lands in the focused field.
What the installer does
- Installs system dependencies
- Creates an isolated virtual environment
- Downloads speech models for your choice
- Sets up desktop integration and PATH
- Creates an application launcher
Uninstall
$ curl -fsSL \
https://raw.githubusercontent.com/jatinkrmalik/vocalinux/main/uninstall.sh \
-o /tmp/vul.sh && \
bash /tmp/vul.shSystem requirements
- OS
- Ubuntu, Debian, Fedora, Arch, openSUSE, or equivalent
- Runtime
- Python 3.9+ with GTK 3 / PyGObject
- Memory
- 4GB minimum; 8GB+ for larger models
- Display
- Microphone plus X11 or Wayland session
- Disk
- ~200MB for the default whisper.cpp setup
Guides by distribution
Distro-specific notes for Ubuntu, Fedora, and Arch, including post-install checks.
Speech engines
Local engines process audio on-device. Remote API is optional for a server you control.
whisper.cpp
DefaultC++ Whisper with Vulkan. Fast install, multi-vendor GPU.
- About 1–2 min default setup
- AMD / Intel / NVIDIA via Vulkan
- Tiny model ~74MB
Whisper
Original OpenAI PyTorch path for NVIDIA CUDA workflows.
- Same model family accuracy
- CUDA when you already live in PyTorch
- Larger install footprint
VOSK
Small footprint for older machines and tight RAM budgets.
- CPU-friendly streaming
- Models around ~40MB
- Great on modest hardware
Remote API
Offload to a server you trust while keeping desktop injection local.
- OpenAI-compatible endpoints
- whisper.cpp server support
- Local VAD still applies
FAQ
Is Vocalinux really 100% offline?
Does Vocalinux collect usage telemetry?
Which Linux distributions are supported?
How do I switch between speech engines?
Can Vocalinux use a remote transcription server?
What happens when I close my laptop lid?
Does Vocalinux preserve my keyboard layout?
Is Vocalinux free?
Voca on other platforms
Related projects for macOS and Windows. This site is about the Linux app.
VocaMac
BetaNative macOS menu bar app. Offline voice-to-text with WhisperKit and CoreML.
VocaLinux
You are hereSystem tray app with whisper.cpp, Vulkan, and full offline support on Linux.
Install and try a real dictation session
Free under GPL-3.0. Local engines by default. Star the repo if it helps your setup.